What is Mean Time to Failure (MTTF) and How to Calculate It

What is Mean Time to Failure (MTTF) and How to Calculate It?
In a busy facility or manufacturing factory with ten thousand products handled every day, downtime can translate to significant financial losses. Equipment downtime is the period during which a machine, system, or piece of equipment is non-operational due to a failure, maintenance, repair, or other unplanned interruption.
This unproductive time can be caused by mechanical breakdowns, software malfunctions, power outages, human error, or scheduled maintenance.
It is an important indicator for businesses seeking to optimize operations in food and beverage manufacturing (or other industries), reduce economic impact, and maintain consistent productivity across manufacturing, technology, and service-oriented industries.
MTTF is a metric that offers more than just a number and benchmark, it provides a strategic and easy-to-understand insight into system durability. Manufacturers, engineers, and business leaders rely on this metric to assess potential risks, optimize maintenance strategies, and ultimately deliver more dependable products to customers.
Whether in high-stakes industries like aerospace and healthcare or consumer electronics, MTTF serves as one of the most important benchmarks for reliability and performance.
In this article, you will learn more about the metric MTTF(Mean Time to Failure), exploring its definition, calculation methods, practical applications, and critical role in modern facilities.
After understanding MTTF, causes of failure, and potential solutions, organizations can transform vulnerabilities into opportunities for enhanced asset reliability in industrial manufacturing and customer satisfaction.

What is MTTF?
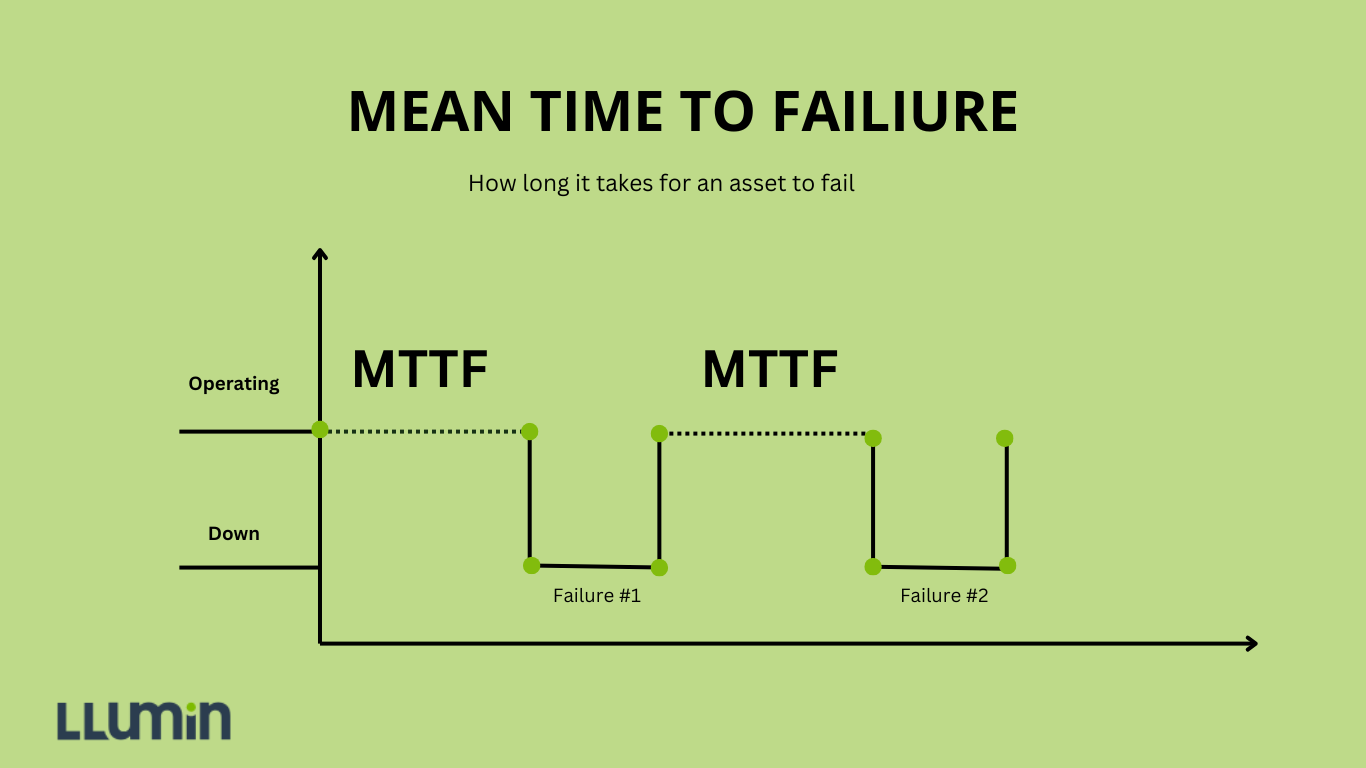
Mean Time to Failure (MTTF) is a maintenance metric that estimates the average operational lifespan of non-repairable assets before they fail.
This measurement reveals essential insights into equipment durability, helping them make strategic decisions about maintenance, purchasing, and inventory management.
MTTF specifically applies to components that are more economically replaced than repaired, focusing on the average time an asset can operate before requiring complete replacement.
The primary value of MTTF lies in its ability to support proactive maintenance strategies and optimize organizational resources.
When businesses understand the expected lifespan of specific components, maintenance teams can develop more effective approaches to equipment management, reducing unexpected downtime and minimizing economic losses.
MTTF enables organizations to transition from reactive maintenance to more strategic, predictive approaches.
Typical assets for which MTTF is calculated include:
- Transistors
- Lightbulbs
- Forklift wheels
- Fan belts
- Conveyor belt rollers
- Motor components
In real-world scenarios, MTTF becomes particularly valuable in high-stakes industries where equipment failure can have significant consequences.
Consider a hospital’s medical imaging equipment, where an unexpected MRI machine breakdown could disrupt critical patient diagnostics.
By tracking the MTTF of key components like cooling systems or magnetic sensors, hospital administrators can proactively schedule replacements before catastrophic failures occur, ensuring continuous patient care and avoiding potential medical emergencies.
In the automotive industry, manufacturers use MTTF to enhance vehicle reliability and safety. Electric vehicle battery systems, for instance, rely on precise MTTF calculations to predict the lifespan of individual battery cells.
Tesla and other manufacturers leverage this data to design more durable battery packs, optimize charging protocols, and provide accurate warranty coverage.
A battery cell with a higher MTTF translates directly into improved vehicle performance and customer satisfaction.
Organizations leverage MTTF for multiple strategic purposes, such as prioritizing high-quality equipment purchases, scheduling preventive maintenance, and establishing just-in-time inventory management. For instance, knowing a part’s precise lifespan allows facilities to order replacements strategically, ensuring continuous operation while avoiding unnecessary inventory costs.
Focusing on assets with higher MTTF, companies can invest in more durable materials, ultimately reducing long-term replacement expenses and operational interruptions.
The fundamental principle behind MTTF is straightforward: it measures the average time a non-repairable asset operates before requiring replacement.
This metric is particularly valuable in scenarios where fixing a component is less economical or practical than simply replacing it. Whether in manufacturing, technology, or service industries, MTTF provides a data-backed approach to understanding and managing equipment reliability, helping organizations make informed decisions that balance performance, cost, and operational efficiency and maintain compliance with pharmaceutical CMMS tools.
Another important metric is AFR.
Annual Failure Rate (AFR) and Mean Time To Failure (MTTF) are interconnected metrics that provide complementary insights into equipment reliability.
AFR represents the percentage of components expected to fail within a year, while MTTF calculates the average operational time before a failure occurs. By converting MTTF into hours per year, organizations can directly translate the expected lifespan of a component into its potential annual failure probability.
The mathematical relationship between MTTF and AFR allows predictive maintenance teams to estimate reliability with precision.
For instance, a component with an MTTF of 50,000 hours suggests an extremely low annual failure rate of approximately 0.02%, indicating high reliability. Conversely, an MTTF of 10,000 hours translates to a higher annual failure rate of around 0.1%, signaling more frequent potential failures.
Here is an example of Backblaze’s failure rates, which can be used as industry benchmarks:

Source: MDPI
How to Calculate MTTF 500
Calculating Mean Time To Failure (MTTF) involves systematically tracking the total operational hours of a group of similar assets and dividing that by the total number of assets in use.
The formula:
MTTF = Total hours of operation ÷ Total assets in use
provides a straightforward method for estimating equipment reliability across various industrial settings.
Consider a telecommunications company managing a fleet of network switches. If 50 identical network switches collectively operate for 15,000 hours before experiencing failures, the MTTF calculation would be:
MTTF = 15,000 hours ÷ 50 switches MTTF = 300 hours
This result indicates that, on average, each network switch is expected to operate for 300 hours before failing. The calculation requires precise tracking of operational hours and maintaining consistent operating conditions across the asset group.
Accurate MTTF calculation demands comprehensive data collection and careful documentation. Organizations must record the total operational time of each asset, ensuring the data represents a representative sample of the equipment’s performance.
This involves monitoring assets under similar environmental conditions, usage patterns, and maintenance protocols to generate meaningful reliability insights.
While the basic calculation appears simple, its implementation requires a rigorous methodological approach.
Factors such as sample size, data consistency, and comprehensive tracking significantly impact the reliability of the resulting metric. By systematically collecting and analyzing operational data, organizations can transform MTTF from a basic statistical measure into a powerful predictive tool for managing technological systems.
Successful MTTF calculations enable proactive maintenance strategies, helping organizations predict potential failures, optimize replacement schedules, and minimize unexpected downtime.
Here is an example of a business calculating its product units’ MTTF, which can be used as a benchmark across various industries:

Source: ResearchGate
Based on the analytical paper, several interesting insights emerge about MTTF and maintenance strategies:
Strategic maintenance approach:
- Reactive maintenance suits low-priority machines with manufacturing reserves
- Preventive maintenance applies to equipment with manufacturing reserves and potential flow interruption risks
- Predictive maintenance is optimal for high-priority machines with no manufacturing reserves
Analytical dimensions:
- MTTF is not a static metric but a dynamic assessment tool
- Gamma distribution provides sophisticated failure probability modeling
- System complexity requires nuanced maintenance strategies
- Failure analysis must consider multiple operational parameters
Key implications:
- MTTF helps categorize equipment based on criticality
- Different maintenance strategies can be applied systematically
- Sustainable development principles should guide maintenance decisions
- Holistic enterprise functionality is central to failure analysis
Methodological insights:
- Use moment-based methods for parameter estimation
- Consider system-wide interactions, not just individual machine performance
- Balance between minimizing maintenance actions and preventing operational disruptions
MTTF vs. MTBF vs. MTTR 500
MTTF, MTBF, and MTTR are all important metrics in reliability engineering and maintenance management, each offering different insights into system performance and reliability.
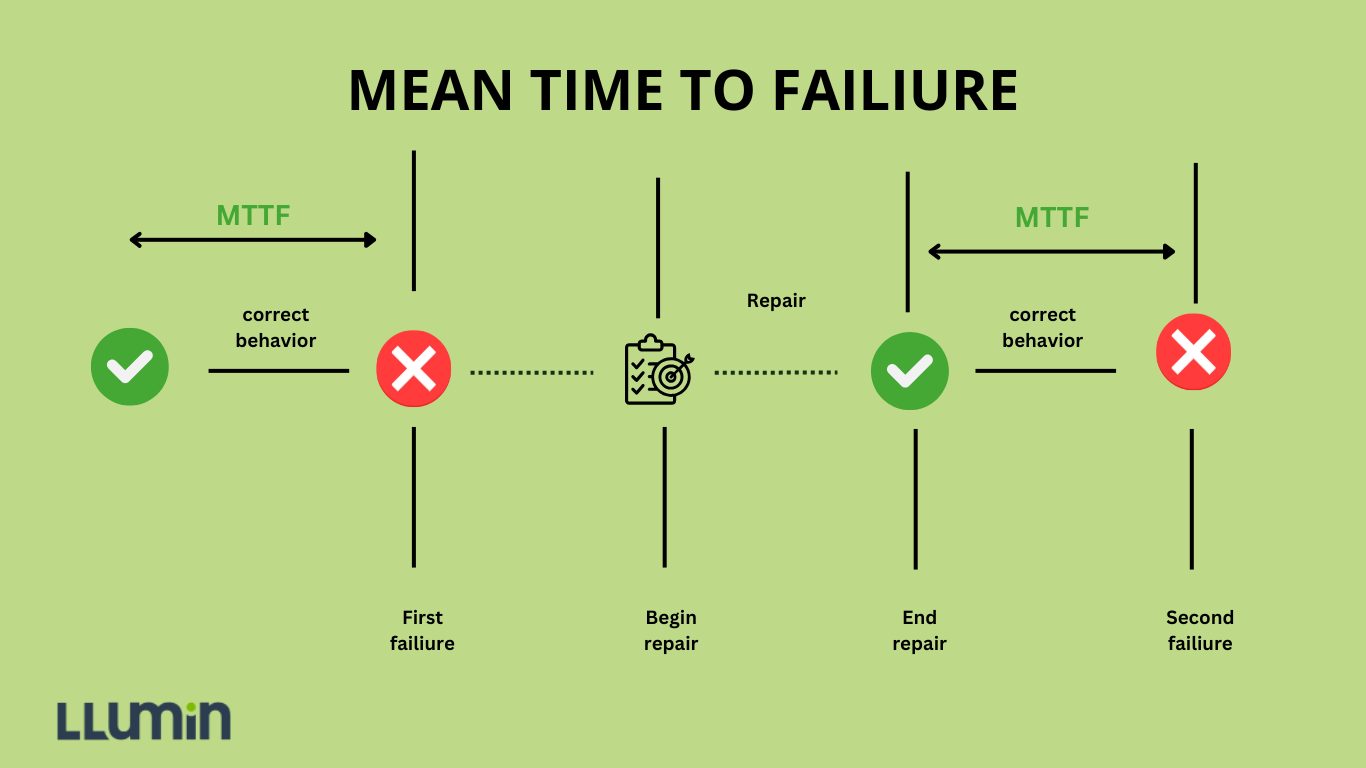
Mean Time To Failure (MTTF) measures the average time a non-repairable system operates before experiencing its first failure, as we explained above in detail.
Mean Time Between Failures (MTBF) indicates the average time between repairable system failures for components that can be fixed rather than completely replaced.
It’s essential in manufacturing, telecommunications, and complex machinery where equipment breakdowns can be costly. MTBF helps organizations schedule preventive maintenance, assess equipment reliability, and optimize maintenance strategies.

A higher MTBF suggests more reliable equipment with less frequent interruptions.
Mean Time Between Failures (MTBF) is a critical reliability metric calculated by dividing total operational time by the number of failures, specifically designed for repairable systems and measured in hours, days, or operational cycles.
In a practical example from a water treatment plant, an industrial pump with 20,000 total operational hours and 4 failures would yield an MTBF of 5,000 hours, indicating the pump experiences a failure approximately every 5,000 operating hours.
Accurate MTBF calculation requires meticulous data collection, careful consideration of sample size, and an understanding of specific operational contexts.
Mean Time To Repair (MTTR) represents the average time required to diagnose, repair, and restore a system to full operational status after a failure occurs. This metric encompasses repair time, parts replacement, testing, and recommissioning. MTTR is critical for understanding system downtime, maintenance efficiency, and overall operational resilience.

Lower MTTR values indicate faster recovery and less productivity loss.
MTTR calculation follows the formula: Total Repair Time / Number of Repairs, typically measured in hours or minutes.
In a manufacturing context, consider an assembly line machine that experiences multiple breakdowns. If the total repair time across four incidents is 12 hours (3 hours per repair), the MTTR would be 3 hours. This metric provides crucial insights into maintenance efficiency and operational downtime, helping organizations understand how quickly they can respond to and resolve equipment failures.
Practical examples illustrate MTTR’s significance across industries. In IT infrastructure, a server failure might involve identifying the issue, replacing faulty components, reinstalling software, and conducting system tests. If these steps typically take 2 hours and occur 6 times a year, the MTTR would be 2 hours, helping IT managers assess their team’s responsiveness and system resilience.
Healthcare provides another compelling MTTR application. Medical equipment like MRI machines requires rapid repair to minimize patient care disruptions.
If a critical diagnostic machine experiences multiple breakdowns with a total repair time of 16 hours across 4 incidents, the 4-hour MTTR indicates the medical facility’s maintenance team’s efficiency in restoring essential diagnostic capabilities.
How are MTTF, MTBF, and MTTR connected?

These metrics are interconnected in assessing overall system reliability. MTTF and MTBF focus on predicting failure occurrences, while MTTR concentrates on recovery speed.
Together, they provide a comprehensive view of system performance, helping organizations minimize downtime, optimize maintenance schedules, and make informed equipment investment decisions.
In practical scenarios, a manufacturing plant might use these metrics to evaluate machinery reliability. A production line with high MTBF, low MTTR, and acceptable MTTF would be considered highly reliable, minimizing unexpected breakdowns and maintenance-related production interruptions.
Conversely, equipment with low MTBF, high MTTR, or short MTTF would signal the need for replacement or significant maintenance improvements.
Causes of Failure
Equipment and system failures can stem from multiple root causes, categorized broadly into mechanical, environmental, human, and design-related factors.
CNC machines in precision manufacturing frequently experience critical failures due to continuous operation, tool wear, and inadequate maintenance. Cutting tools degrade over time, leading to reduced product quality, increased dimensional inaccuracies, and potential complete machine shutdown.
Regular calibration, tool replacement, and predictive maintenance are essential to mitigate these risks.
Automated manufacturing systems depend on precise robotic operations. Servo motor failures, control system errors, sensor misalignment, and software glitches can cause significant production interruptions.
Modern manufacturing relies heavily on these systems, making their reliability crucial to maintaining production efficiency and quality standards.
Mechanical failures often originate from component wear, material fatigue, lubrication issues, and unexpected stress loads that gradually degrade system integrity.
Environmental factors significantly contribute to failure mechanisms, including:
- Temperature extremes causing material expansion or contraction
- Humidity and corrosive atmospheres degrade component surfaces
- Vibration and mechanical shock
- Electromagnetic interference disrupting electronic systems
- Dust, debris, and particulate contamination
Human-related causes represent a critical failure domain, encompassing issues like inadequate maintenance, improper operation, insufficient training, and human error during installation or repair processes.
Operational mistakes can introduce unexpected stresses, misalignments, or procedural deviations that compromise system reliability and accelerate component degradation.
Design-related failures emerge from fundamental engineering limitations, including material selection errors, insufficient stress testing, inadequate tolerance calculations, and oversimplified failure mode analyses.
Complex systems often reveal unexpected interaction points where component interfaces create vulnerability, leading to cascading failure scenarios that exceed initial design assumptions.
Technological complexity introduces additional failure risks, with interconnected systems presenting multiple potential failure modes. Software integration, communication protocol limitations, and embedded system interactions create intricate failure landscapes where individual component reliability becomes increasingly challenging to predict and manage.
Statistical analysis reveals that most failures result from multiple interconnected causes rather than single isolated events.
Comprehensive failure prevention requires holistic approaches integrating predictive maintenance, rigorous testing protocols, continuous monitoring, and adaptive design strategies that anticipate potential failure mechanisms across mechanical, environmental, human, and technological domains.
Solutions
To minimize downtime, reduce repair costs, and maintain optimal operational performance, facilities need a thorough approach to equipment management.
Different types of maintenance approaches provide solutions to expanding the lifespan of an asset and prolonging MTTF. Here are the most popular approaches:
Preventive maintenance
Preventing machine failure requires a systematic, technology-driven strategy focused on proactive maintenance techniques.
Preventive maintenance forms the core of this approach, involving regular equipment inspections, systematic cleaning, precise calibration, and timely component replacements.
Organizations can identify potential issues by implementing comprehensive maintenance logs and tracking systems before they escalate into critical failures.
For example, Toyota’s automotive assembly lines use comprehensive maintenance schedules, and robotic welding arms undergo regular lubrication, calibration, and component inspections.
Each robot’s maintenance log tracks precise performance metrics, allowing technicians to predict and prevent potential failures before they disrupt production.
Predictive maintenance
Predictive maintenance helps with equipment management through advanced technologies like machine learning, sensor-based monitoring, and real-time data analytics.
Programmable logic controllers enable continuous tracking of machine performance, monitoring critical parameters such as vibration, temperature, and operational efficiency. This data-based approach allows facilities to anticipate potential breakdowns with remarkable precision.
For example, modern wind turbine farms use advanced predictive maintenance technologies: sensors embedded in turbine components continuously monitor vibration, temperature, and rotational speed.
In addition, machine learning algorithms analyze this data to detect subtle performance variations that might indicate impending mechanical stress.
When abnormal patterns occur, maintenance teams can proactively schedule repairs, preventing potential catastrophic failures.
LLumin’s CMMS+ is a “must-have” software for predictive maintenance. Its cloud-based platform enables real-time equipment performance tracking, so businesses can identify potential failures before they occur, preventing costly operational disruptions.

The software provides precise maintenance scheduling based on actual equipment data. LLumin analyzes performance metrics and helps companies optimize resource allocation and reduce unexpected repair costs. Its mobile-ready interface allows instant access to real-time maintenance insights.
LLumin transforms maintenance from reactive to proactive strategies. The system delivers data-backed decision-making capabilities, extending equipment lifespan and improving operational efficiency with energy management software.
Whether for large corporations or small operations, LLumin offers a scalable, easy-to-use solution to industrial equipment management.
Request a demo of LLumin to see it in action!
Diagnostic analytics
By collecting and analyzing comprehensive performance data, organizations intelligently allocate resources, addressing specific equipment vulnerabilities and minimizing unnecessary interventions.
The integration of monitoring technologies enables more accurate prediction of maintenance needs.
We can see the power of diagnostic analytics through petroleum refineries. Advanced monitoring systems track thousands of parameters across complex processing equipment.
By analyzing historical performance data, predictive models can identify specific equipment vulnerabilities. For example, a refinery might detect that a particular type of pump experiences increased wear under specific operational conditions, allowing for targeted maintenance interventions.
Conclusion
In this article, we summed up the main causes of machine failure in an industry or facility setting, important metrics like MTTF, MTBF, and MTTR, and solutions that prolong assets’ life.
It is important for facilities to track data and calculate MTTF regularly so they don’t end up with delays and unexpected machine breakdowns, but it is equally important to work on preventive and predictive maintenance.
Predictive and preventive maintenance helps keep everything on track and minimizes downtime and unexpected machine failures. With a CMMS+ like LLumin, workers can access data and asset information at all times.
Take a free tour of LLumin to see how it works!
Getting Started With LLumin
LLumin develops innovative CMMS software to manage and track assets for industrial plants, municipalities, utilities, fleets, and facilities. If you’d like to learn more about the total effective equipment performance KPI, we encourage you to schedule a free demo or contact the experts at LLumin to see how our CMMS+ software can help you reach maximum productivity and efficiency goals.
Take a Free TourFAQs
Why is MTTF important?
Mean Time To Failure (MTTF) is a reliability metric that represents the average time a non-repairable component operates before failing. It is an important benchmark for organizations because it provides insights into equipment lifespan, helps predict potential failures, and enables proactive maintenance planning. If they understand their MTTF, businesses can optimize their operational strategies, reduce unexpected downtime, and make informed decisions about equipment replacement and system design.
How can I improve the reliability of my systems?
To improve a system’s reliability business a comprehensive approach that includes selecting high-quality components, implementing regular maintenance protocols, and designing systems with redundancy. Organizations should focus on continuous performance monitoring, conducting periodic reliability assessments, and training personnel on proper equipment handling. Advanced predictive maintenance techniques and statistical analysis can help identify potential failure points and develop more robust system designs.
What industries commonly use MTTF as a metric?
MTTF is an important metric across multiple industries that rely on complex technical systems. Manufacturing, electronics, aerospace, automotive, healthcare equipment, telecommunications, and energy infrastructure extensively use MTTF to assess and manage equipment reliability. In these sectors, understanding the expected operational lifespan of components is needed for maintaining operational efficiency, ensuring safety, and minimizing economic losses due to unexpected equipment failures. Explore CMMS solutions for the oil and gas industry!
What tools or software can help calculate MTTF?
Many organizations use custom spreadsheet calculations and advanced predictive maintenance platforms to track and analyze equipment performance data, enabling more accurate MTTF predictions and more effective maintenance strategies. There are also dedicated reliability software like ReliaSoft and Weibull++, statistical analysis platforms such as MATLAB and R, and enterprise asset management systems.

With over two decades of expertise in Asset Management, CMMS, and Inventory Control, Doug Ansuini brings a wealth of industry knowledge to the table. Coupled with his degrees in Operations Research from both Cornell and University of Mass, he is uniquely positioned to tackle complex challenges and deliver impactful results. He is a recognized expert in integrating control systems and ERP software with CMMS and has extensive implementation and consulting experience. As a senior software architect, Doug’s ability to analyze data, identify patterns, and implement data-driven approaches enables organizations to enhance their maintenance practices, reduce costs, and extend the lifespan of their critical assets. With a proven track record of excellence, Doug has established himself as a respected industry leader and invaluable asset to the LLumin team.